
Partager cet article
Dans notre série de l’été sur l’intelligence artificielle, nous essaierons de dresser un tableau des enjeux majeurs autour de l’intelligence artificielle: qu’est ce que l’IA ? comment différents secteurs ont été transformés par son apparition ? Quels en sont les avantages et les dangers dans le domaine de la cybersécurité ?
Ces dernières décennies, c’est par la fiction que le public a été majoritairement introduit à la figure de l’intelligence artificielle: les répliquants de Blade Runner, les droïdes de Star Wars ou HAL dans 2001- Odyssée de l’Espace ont marqué les esprits, mais peu de gens imaginaient qu’ils pourraient un jour devenir réalité. Grâce aux progrès réalisés dans les domaines du deep learning ou du traitement du langage naturel, l’IA n’est plus un rêve futuriste, mais bel et bien une réalité contemporaine. Mais comment en est-on arrivés là ? C’est ce que nous allons découvrir dans cette première partie.
L’objectif de l’IA est de créer des algorithmes ou des méthodes qui permettent aux ordinateurs d’apprendre par eux-mêmes à partir de données, d’expériences et d’interactions avec le monde qui les entoure. C’est de cette façon que se comporte l’intelligence humaine: nous acquérons des connaissances et apprenons à comprendre en observant le monde qui nous entoure, par une méthode d’essais et d’erreurs, en réfléchissant à nos expériences. En interagissant avec le monde, nous recevons constamment de nouvelles informations et les utilisons pour améliorer notre compréhension du monde.
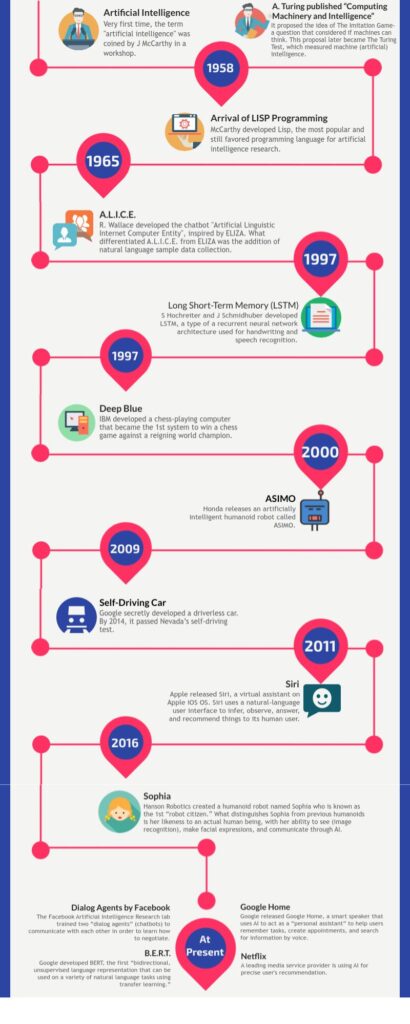
Dans les années 1950, le mathématicien Alan Turing invente un test d’intelligence artificielle supposé répondre à la question “les machines peuvent-elle penser”: si un humain converse avec deux entités, un humain et une machine, et n’est pas capable de déterminer lequel de ses interlocuteurs est l’humain et lequel la machine, c’est que la machine aura passé le test.
Dans les années 2010 un certain nombre de machines se sont approchées du succès, sans qu’il existe un consensus sur leur nombre exact, ni même sur le fait si le test a été réellement réussi. La plupart du temps, l’on considère que l’IA Eugene Goostman, qui a persuadé 30 humains qu’il était un jeune garçon ukrainien de 13 ans par le biais de conversations textuelles d’environ 5 mn, est celui qui s’en est approché le plus en 2014.
Le terme “intelligence artificielle” a été choisi par John McCarthy en 1956 lors de la conférence de Dartmouth, dont l’objectif était d’étudier l’intelligence en détail, de façon à ce qu’une machine puisse être fabriquée pour la simuler.
Dans les années 1960 et 1970, la recherche en IA s’est orientée vers le développement de systèmes experts conçus pour imiter les décisions prises par des spécialistes humains dans des domaines définis. Ces méthodes ont été fréquemment utilisées dans des secteurs tels que l’ingénierie, la finance et la médecine.
Dans les années 1980, les programmes ont commencé à s’intéresser à l’apprentissage machine, et ont pu résoudre des problèmes d’algèbre formulés de façon verbale et non numérique; c’est alors que l’on assiste à la première utilisation des langues par les IA – ce qui finira par mener au Chat GPT que l’on connaît. C’est ainsi que les réseaux neuronaux ont été créés et modelés sur la structure et le fonctionnement du cerveau humain.
Les années 1990 ont été marquées par un changement d’orientation vers l’apprentissage automatique et les approches fondées sur les données, grâce à la disponibilité accrue des données numériques et aux progrès de la puissance de calcul. Cette période a vu l’essor des réseaux neuronaux et le développement des machines à vecteurs de support, qui ont permis aux systèmes d’IA d’apprendre à partir des données, ce qui s’est traduit par une amélioration des performances et de l’adaptabilité. C’est aussi à cette époque que le langage naturel commence à être simulé de façon particulièrement réaliste notamment par les programmes STUDENT ou ELIZA – le tout premier chatbot.
Les choses se sont particulièrement accélérées ces 20 dernières années. Au début des années 2000, les progrès en matière de reconnaissance vocale, de reconnaissance d’images et de traitement du langage naturel ont été rendus possibles par l’avènement de l’apprentissage profond (deep learning), une branche de l’apprentissage automatique qui utilise des réseaux neuronaux profonds (deep neural networks).
Enfin, dans les années 2010 l’IA est devenue une part réellement visible de notre quotidien: smartphones, assistants virtuels, chatbots présents sur de nombreux sites commerciaux, jusqu’à la révolution GPT.
L’explosion récente de l’IA est largement attribuée au développement des techniques d’apprentissage profond et à l’émergence de réseaux neuronaux à grande échelle, tels que la série Generative Pre-trained Transformer (GPT) d’OpenAI.
En 2015 Open AI est co fondée par Elon Musk, Sam Altman , Greg Brockman , Ilya Sutskever, John Schulman et Wojciech Zaremba. Les fondateurs étaient conscients à la fois du potentiel comme du risque de l’IA et voulaient promouvoir ces technologies d’une façon qui préserverait la sécurité.
L’association se transforme en société en 2019 et signe en 2023 un partenariat avec Microsoft: « Aujourd’hui, nous annonçons la troisième phase de notre partenariat à long terme avec OpenAI par le biais d’un investissement pluriannuel de plusieurs milliards de dollars visant à accélérer les percées en matière d’IA afin de garantir que ces avantages soient largement partagés avec le monde. » (Déclaration de l’entreprise à l’occasion de cette fusion).
Si pour le moment il est encore facile de repérer des faiblesses dans les IA actuelles, la vitesse exponentielle de leur développement nous laisse penser que nous sommes à l’aube d’un immense bouleversement de la technologie, et par là même du monde, du fait des changements que ces IA apportent dans notre quotidien mais aussi dans un nombre croissant de professions. Cet article n’a pas été écrit à l’aide de chat GPT… mais aurait-il pu l’être ? Très certainement ou presque, tout comme le code contenu dans cette page web.

Nous verrons dans la suite de notre série comment différentes industries évoluent du fait de l’introduction de ces IA, et quelles peuvent être les répercussions, positives, et négatives en matière de cybersécurité.
Dans l’intervalle, n’hésitez pas à nous contacter si vous avez un contenu à protéger, et revenez nous lire en août, pour la suite de notre série sur les intelligences artificielles.
Partager cet article